Clustering independent of sampling in observational studies
Author
George Savva
Introduction
We know that random sampling is important to get good inferences from epidemiological studies.
If sampling is ‘clustered’ then we need to account for this in our analysis. This is well known.
However we may have a situation where data points are generated in clusters, but we still sample them randomly. Is there a risk of false positive associations in such situations? How should we deal with it?
Here I use a simple simulation to show that even with random sampling, data that is generated in clusters can still lead us to false positive conclusions.
Simulation data
The research question here is whether there is a difference between two populations.
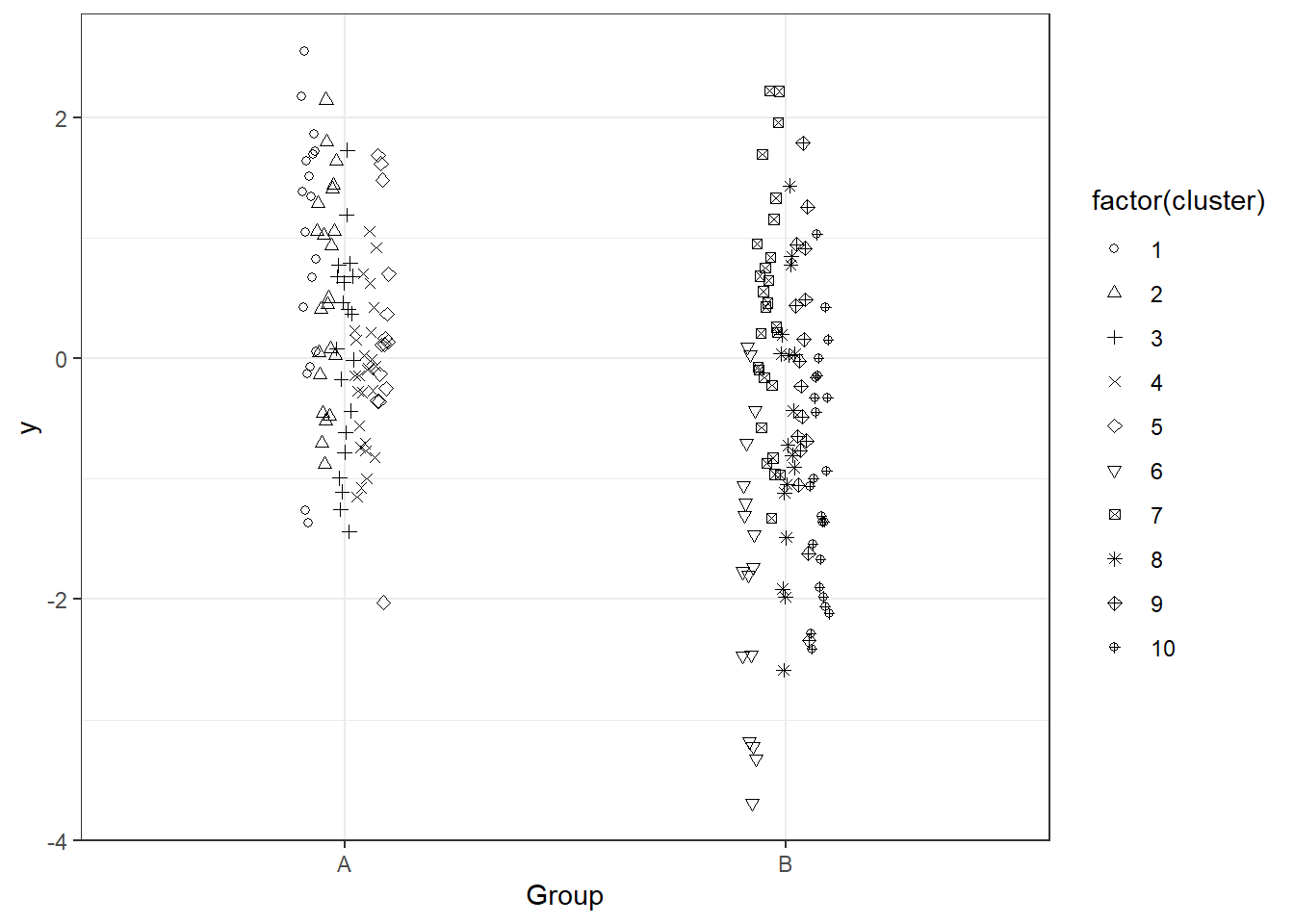
For the simulation I will create a dataset of 100 points from each population. Each point is sampled independently at random, but arises from one of five clusters in each population. So, to sample each point we first select a cluster at random, then generate a point from that cluster.
The cluster averages in turn are selected from a normal distribution with mean zero.
An real example question might relate to whether there is a difference in educational attainment between two different cities. We can select children from each city completely at random. But if each city has only five schools then the data points are clustered by school, even if the children are selected completely randomly without any reference to which school they attend.
So although children are selected independently of each other, they are still clustered in some sense! Do we still need to run a ‘clustered’ analysis if we are interested in understanding whether ‘city’ has any effect on educational attainment?
Remember we know that there is no effect of city on average school outcome in our simulation. Differences in outcomes do occur completely randomly at the school level and at the individual child level.
Nclusters <-10clustersMeans <-rnorm(Nclusters, 0,1)## Suppose group A come from clusters 1 to 5## Group B come from clusters 6 to 10.NperGroup <-100GroupAClusters <-sample(1:5,NperGroup, replace=TRUE)GroupBClusters <-sample(6:10,NperGroup, replace=TRUE)dat <-data.frame(Group=rep(c("A","B"),each=NperGroup), cluster=c(GroupAClusters, GroupBClusters))dat$y <-rnorm(NperGroup*2 , clustersMeans[dat$cluster], 1)head(dat)
Group cluster y
1 A 1 2.17314644
2 A 4 0.23199408
3 A 4 -0.14176686
4 A 2 1.05632863
5 A 4 0.15161343
6 A 3 0.08051086
## While mixed model taking the clustering into account does notlmer(y ~ Group + (1|cluster), data=dat) |> broom.mixed::tidy() |>subset(effect=="fixed")
So if we ignore the clusters we get a false positive result (p<0.001), but if we incorporate them into our analysis we do not.
Type 1 error rate
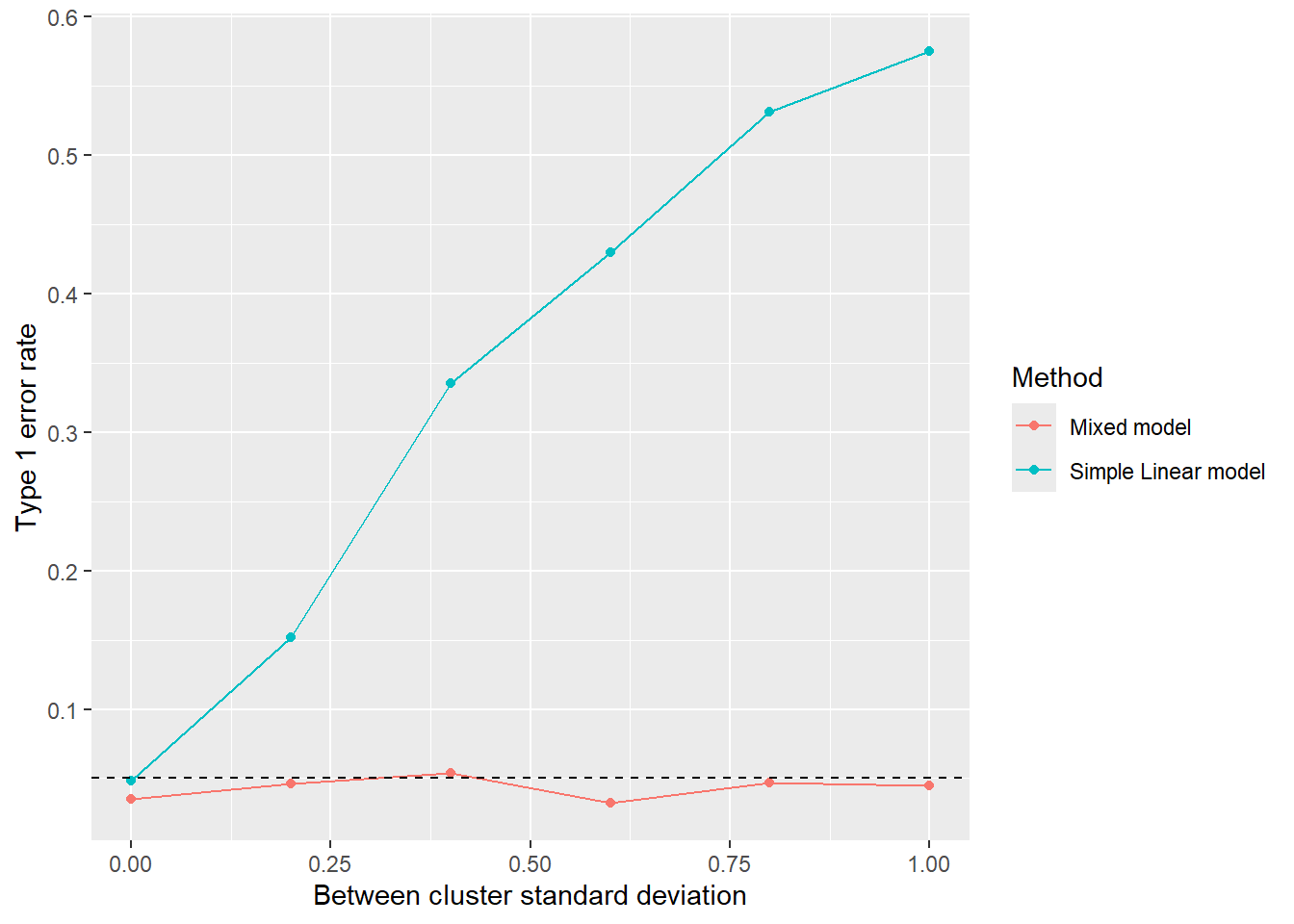
To quantify the problem we can look at how the false positive rate changes with the extent of the clustering.
We’ll simulate datasets and analysis 1000 times for each value of the cluster standard deviation, from 1.0 (the same as the between individual standard deviation) to zero. Then we’ll look at the proportion of statistically significant results (p<0.05), and compare this to the nominal 5% rate.
In each simulation we generate new cluster means, and then a new dataset of points. We then apply the simple linear model and a mixed effects model, and extract the p-values for the hypothesis test that the effect of ‘population’ is zero.
The type 1 error rate increases markedly with the among of variance between ‘clusters’ when a simple linear model is used. A mixed model broadly corrects this, and may over-compensate when the between-cluster variance is very low.
So for our school analogy, if schools are very variable, then if we don’t model the clustering it may look like there are inherent differences between cities instead of there simply being random differences between the schools that are not attributable to the city they are in.
Whether this is the correct or incorrect answer depends on exactly what the question is that we are trying to answer, that is whether we are trying to (1) identify the city that just happens (by chance) to have the best schools, or (2) whether we are asking about whether the city itself promotes good schools or good outcomes.
In most situations we are asking the latter question in which case we need to include the grouping in our analysis to get a meaningful result.
To generate our simulated datasets we included no effect of the grouping factor on the cluster means or the individual means, and we sampled each unit independently from the population. Yet a simple linear model (equivalent of t-test or ANOVA) returned a strongly significant effect. This was corrected by considering the shared variance within clusters in our model.
This should be another reminder that to avoid looking silly we need to understand how our datasets come to be, and what shared variance there is between our observations, even if we know that our samples are generated from our populations using simple random sampling.