This file will include short simulations to understand how differences in community compositions are reflected in alpha and beta diversity metrics.
In each simulation I’ll create some data with given characteristics then look at how this is reflected in the diversity measures. This could be extended into power calculations if needed.
Simulation 1
We’ll assume that there are 100 possible species in my communities.
There are two different classes of environments from which we can sample communities,
In samples from the first environment each species is present with probability 0.4.
In samples from the the second environment each species is present with probability 0.5.
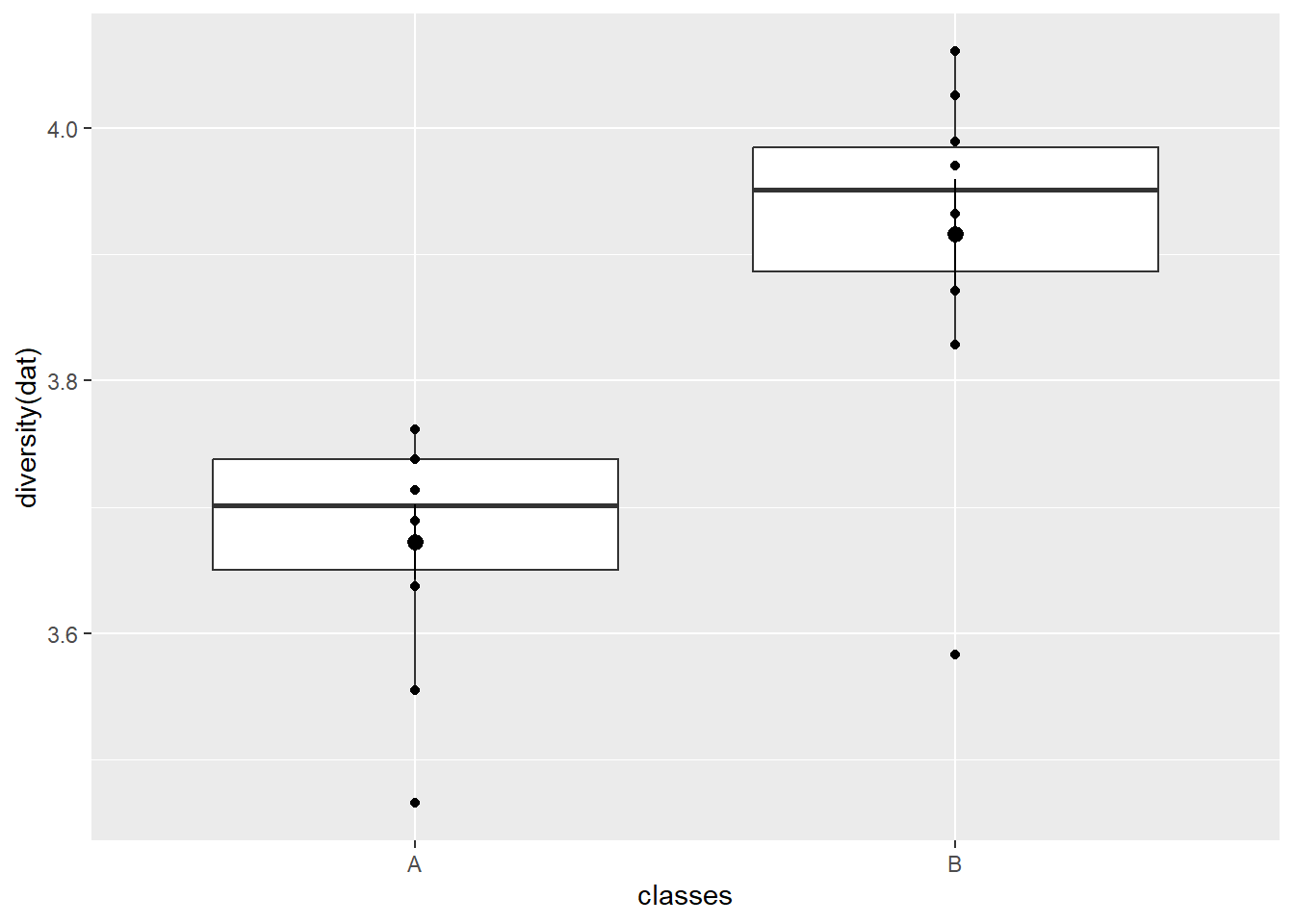
We’ll sample ten communities per class, and look at their alpha and beta diversities
First sample a matrix of the community compositions:
N =10# Number of samples per classn =100# Number of possible speciesset.seed("19122023")classes <-rep(c("A", "B"), each=N)classProbabilities <-c("A"=0.4,"B"=0.5)dat <-sapply(classes, \(class) rbinom(n=n, size =1, p=classProbabilities[class])) |>t()# Check it looks OKdat[1:10,1:10]
Welch Two Sample t-test
data: diversity(dat) by classes
t = -4.6706, df = 16.102, p-value = 0.0002517
alternative hypothesis: true difference in means between group A and group B is not equal to 0
95 percent confidence interval:
-0.3544225 -0.1332105
sample estimates:
mean in group A mean in group B
3.672421 3.916238
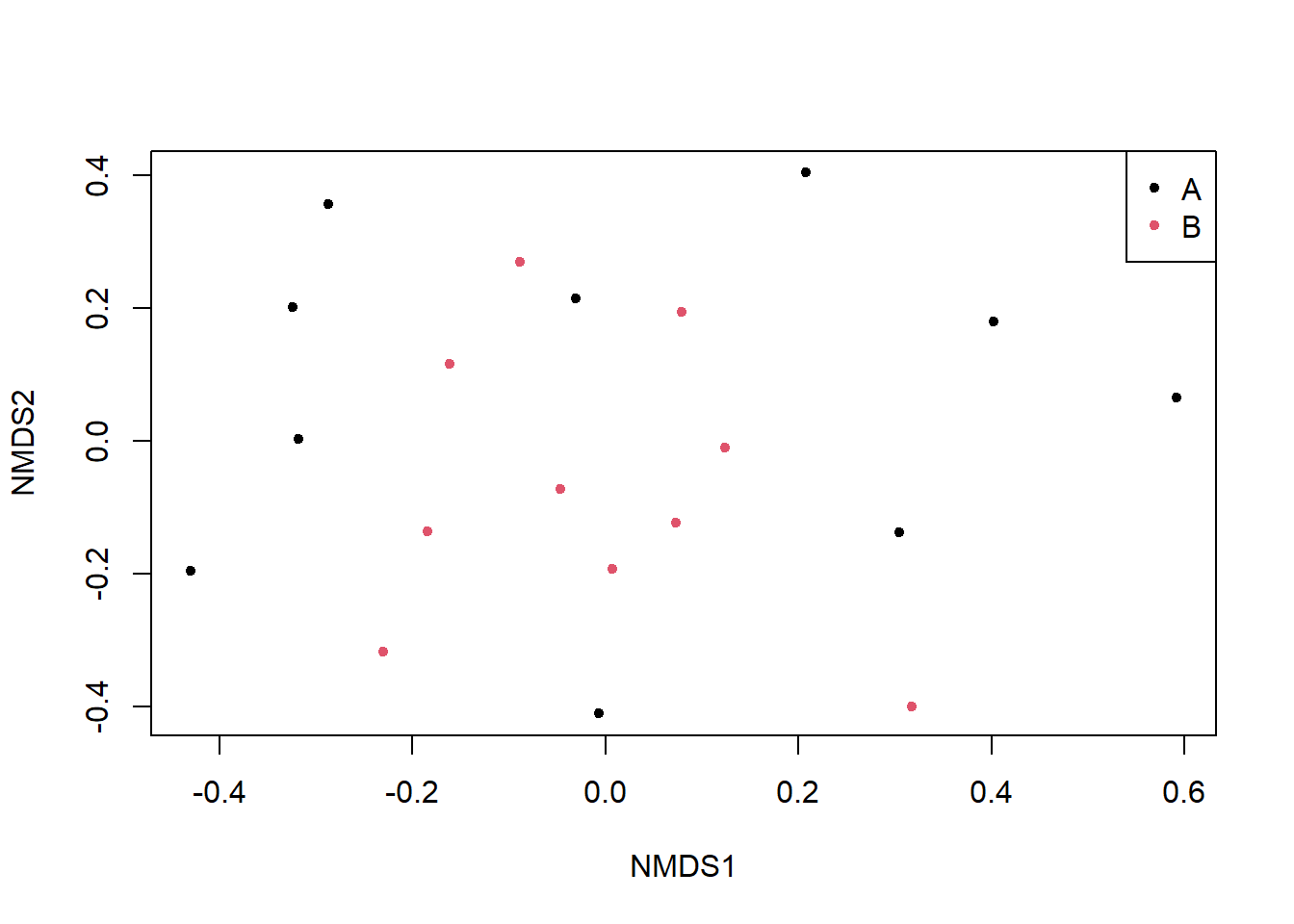
Beta-diversity (NMDS following Jaccard diversity):
## Not so clear with the beta-diversityvegdist(dat, method ="jaccard", binary =TRUE) |>metaMDS(trace =0) |>scores() |>plot(col=factor(classes), pch=20)legend("topright", legend=c("A","B"), col=1:2,pch=20)
Permutation test for adonis under reduced model
Permutation: free
Number of permutations: 999
adonis2(formula = dm1 ~ classes)
Df SumOfSqs R2 F Pr(>F)
Model 1 0.2915 0.06188 1.1873 0.166
Residual 18 4.4193 0.93812
Total 19 4.7108 1.00000
So in this case we see a clear difference in alpha diversity between sites but it’s not so clear for beta diversity. It looks like the environment B samples are slightly more clustered while the A samples are more spread out. The difference is not reflected in a PERMANOVA (via adonis2) or ANOSIM.
This is a good reminder that important differences in community composition might not be immediately visible in beta diversity plots. Maybe you all know that anyway but it was a good reminder for me.