Plotting data is an essential part of data analysis and reporting. Your plots communicate your results, and a good plot can be the difference between a successful and unsuccessful communication.
In this session we’ll think about how to plot your data, what makes a good vs a bad plot, and illustrate some concepts for plotting using R.
Learning objectives:
What to plot
A few principles for designing a good graph
Plotting in R with ggplot
What to plot
Figures are an important aspect of scientific communication. They can communicate patterns
Your data is likely to be complex, and you will have limited space for plotting in your reports, and so you should think carefully about which plots are important and how to choose to display your data.
Generally there are two reasons to plot data, that mirror the two main types of statistical analyses we can perform.
The first is to describe data (mirroring our descriptive analyses), the second is to describe results that come from the data (mirroring our inferential analyses). Often we are forced to meet these two objectives in the same graph, which can cause some tension!
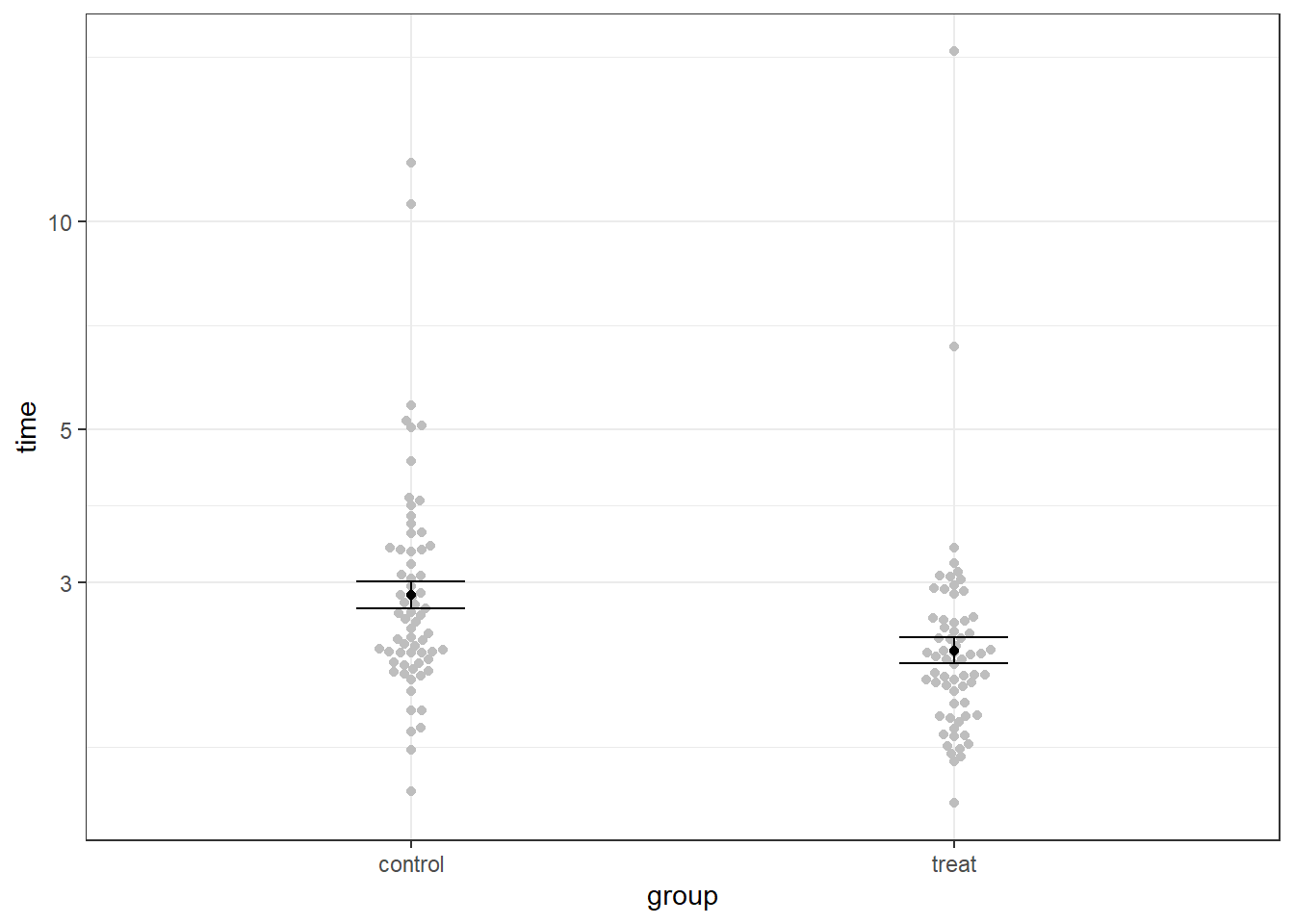
Walking speed data
Consider our walking speed data. Recall our aim was to test whether a rehabilitation intervention improves walking speed. We had data from a clinical trial among older men and women recruited from several hospital departments.
What are the different reasons we might make plots of the data? Which plots did we make in Day 2, and why? What did we learn from them, or what were we trying to communicate
In each case, who is the audience and what information to we want to extract or display?
Some uses for graphics (click to expand)
Graphs to describe your dataset
See the data!
For ourselves / collaborators / readers
Distribution of data
Describe population
Find outliers or other problems
Preliminary comparison of means
Choose a valid statistical method
Graphs to describe scientific results
See the results!
For ourselves / collaborators / readers
Validate a statistical model
For scientific publications and presentations:
Show effect size
Show confidence or uncertainty in effect size
Show statistical significance
Public communication of findings
These aspects might all need kinds of different plots at different stages of the project.
Each plot we produce needs to meet its own need. We should think about what we want to see, and then work out how to get it.
Descriptive plots
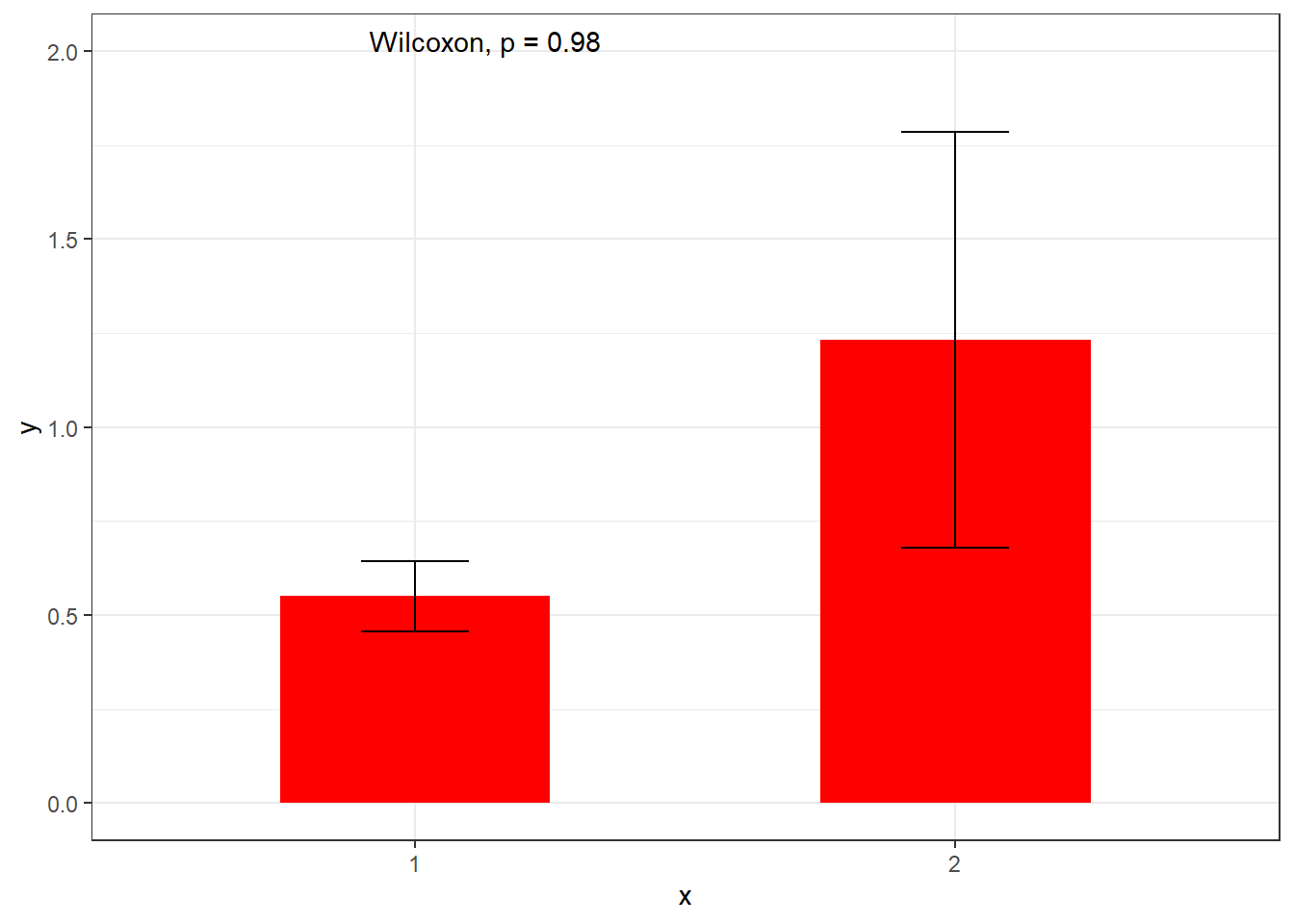
Before we model data we should visualise it. This crucial first step is often omitted in analyses and reports. Consider the follow example, that I have designed after a real analysis I was asked to comment on, where an outcome was compared between two treatment conditions:
library(ggplot2)library(ggpubr)set.seed(12345) # Set seed is used to ensure that 'random' samples will come out the same each time.N=12y <-c(runif(N), c(runif(N-2), 4.5,6))x <-factor(rep(c(1,2), each=N))ggplot(data.frame(Group=x,y), aes(x,y)) +stat_summary(geom="col",width=0.5, fill="red") +stat_summary(geom="errorbar", width=0.2) +theme_bw()+stat_compare_means(label.y =2)
On the face of it, it looks like the outcome is higher in group 2 than group 1. If this is all you see then this is surely the conclusion you would come to.
But why is the p-value so high? And how well do you feel like you understand the data from this graph?
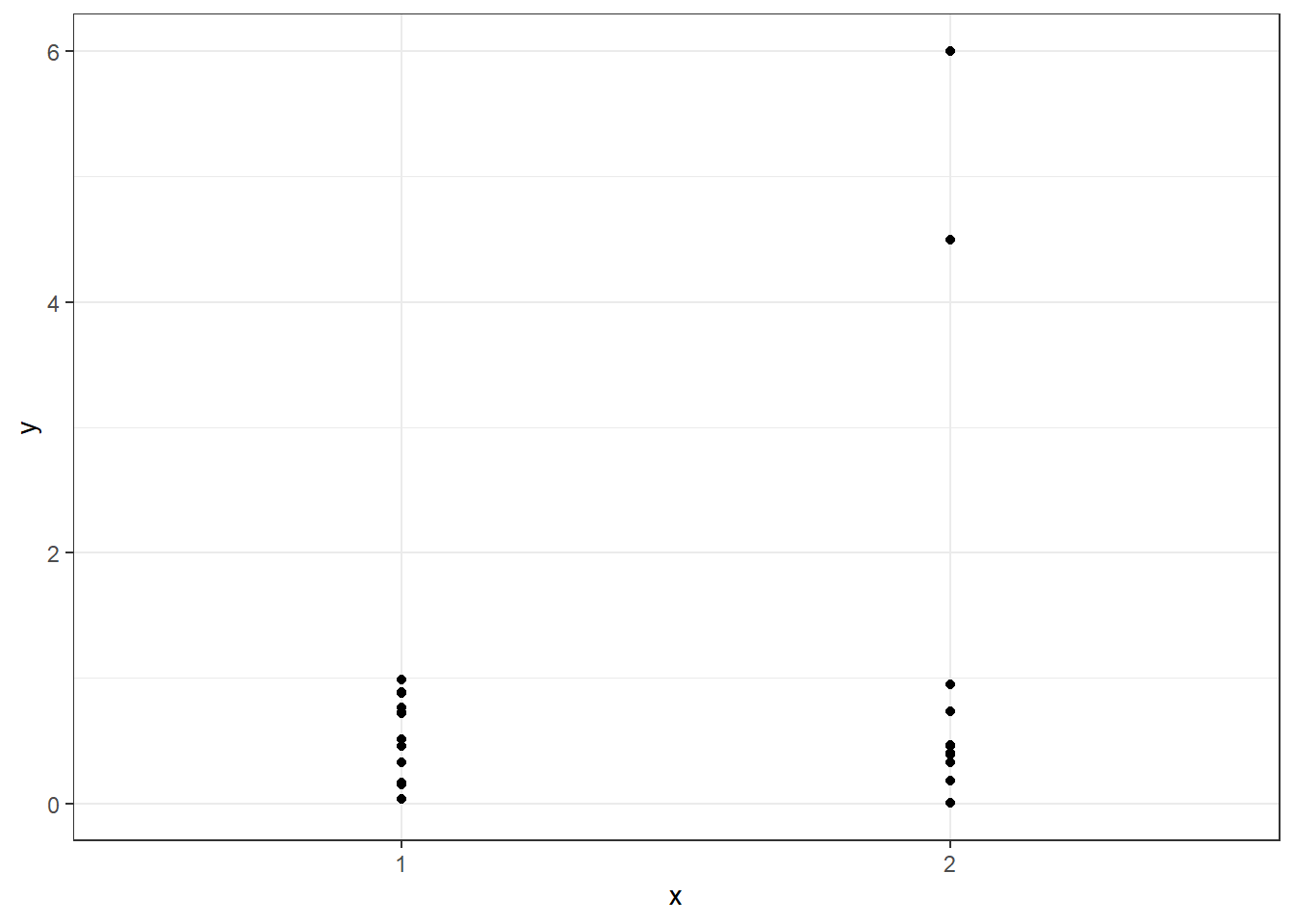
Quite differently? At least with this second visualisation we can see the data and draw our conclusions about what is going on directly.
Also consider, the first graph only shows you four values, two means and two standard errors (if that is what they are, I never actually told you). It’s a waste of ink. But how often do you see this first presentation in the scientific papers your read? When I see one of these I can’t help but wonder what horrors it is hiding.
The second graph tells us quite a lot. It tells us to maybe check our outlying data points, or to try transforming our data before analysis. We might even conclude that the two groups are more-or-less the same, except for two individuals, which may well be a real effect of treatment that is limited to specific individuals. In any case we learn a lot.
So our most important rule is: always plot your data, and not just summaries of the data.
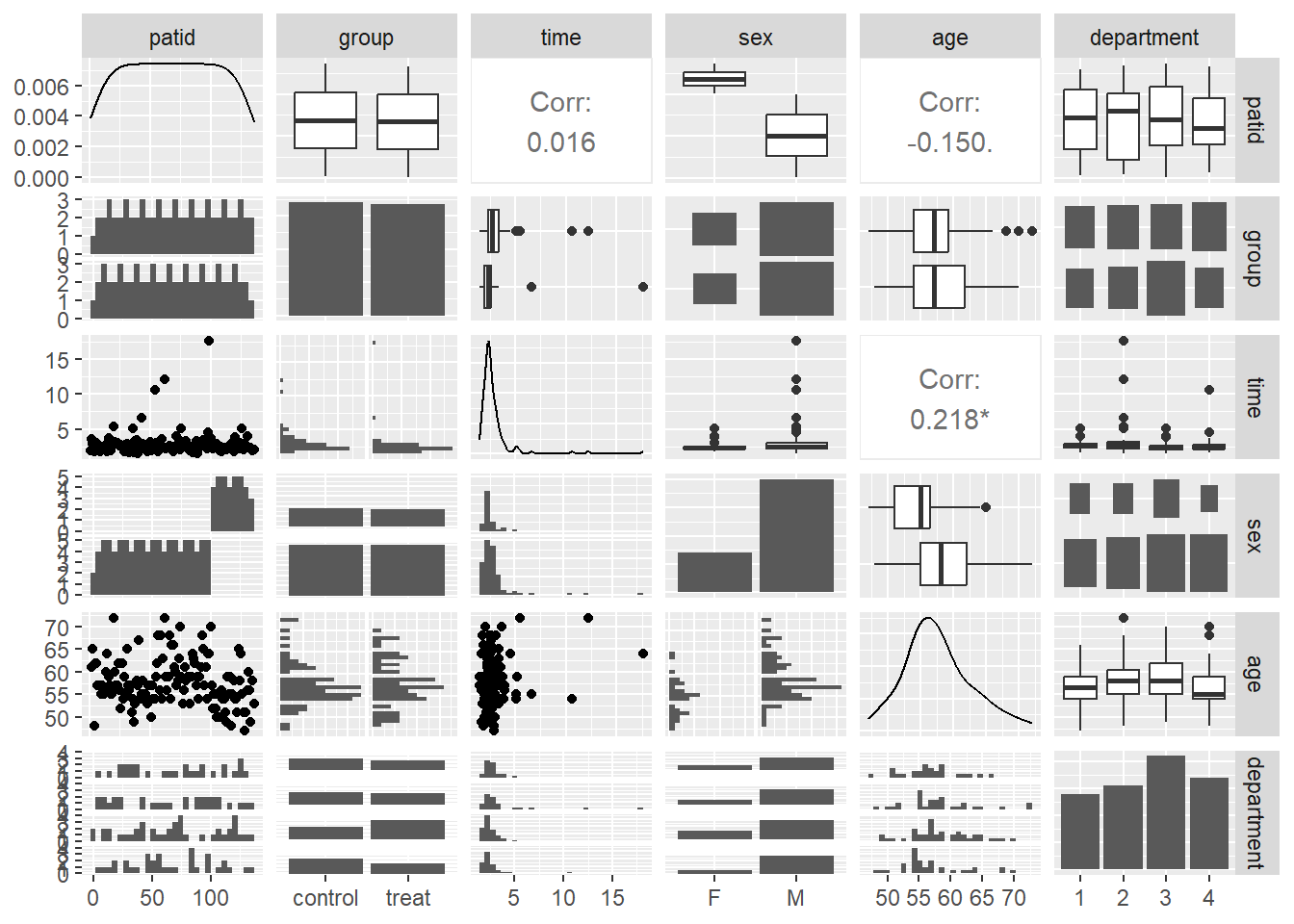
Ideally, if we have a dataset with several variables, we will start by making something like a graph matrix showing every variable against every other variable. This will help us identify any potential problems or outliers in 2-dimensions.
The ggpairs function in the GGally package gives us a grid layout showing all of these combinations. I think its a reasonable summary.
Note I’m not wasting a lot of time making this graph pretty. It’s for me only, I don’t care what it looks like, I just want to see the data as quickly and as effectively as possible. I’ve also left patient ID in here as a variable, there’s no harm doing this, and it might show me if any data errors have occurred.
Does this graph meet the objectives that we set out for our ‘descriptive’ analyses above?
Inferential graphs
While the descriptive graphs tells us about the data, it doesn’t tell us much about the comparison we are interested in making.
To think about how we could graph that, first think about what exactly it is we are trying to show.
Lets go back to our linear model from last time:
model1 <-lm(data=walkingdata, log(time) ~ group + sex + age + department)gtsummary::tbl_regression(model1)
Characteristic
Beta
95% CI1
p-value
group
control
—
—
treat
-0.18
-0.30, -0.07
0.003
sex
F
—
—
M
0.04
-0.10, 0.19
0.6
age
0.01
0.00, 0.03
0.021
department
1
—
—
2
0.11
-0.07, 0.28
0.2
3
-0.09
-0.26, 0.07
0.3
4
-0.06
-0.23, 0.12
0.5
1 CI = Confidence Interval
What is the key information here that we need to communicate?
We should say what our estimate of the treatment effect is, and how sure we are of this. That is the ‘actionable’ result from this work, and that is what we want people to take away from our analysis. The fact of the treatments being ‘significantly’ different is interesting but not enough on its own. So from our analysis we should be trying to communicate the estimate of treatment effect, the standard error of treatment effect, and potentially the p-value and a confidence interval for the difference.
The mean time in each group is perhaps interesting descriptively, so people can understand our sample. It’s hard to see why the standard error within each group should be of interest.
So - do I even need a graph? Should this summary statistic, mean difference = 0.19 (standard error=0.06; p=0.0015) be enough? Recall that this was calculated on a logarithmic scale, so it’s probably best to exponentiate it and report a ratio:
contrast ratio SE df lower.CL upper.CL
treat / control 0.832 0.0499 124 0.739 0.937
Results are averaged over the levels of: sex, department
Confidence level used: 0.95
Intervals are back-transformed from the log scale
So we could say “times for treated group were 83% of the times for the control group (95% CI=74% to 93%)”. Or: “treatment improved times by 17% (95% CI=7-26%).”
Is this enough? I think so, if combined with a visual summary that persuades us that the model is reasonable, and we have the descriptive graph that shows us this difference in the context of the variance in the data.
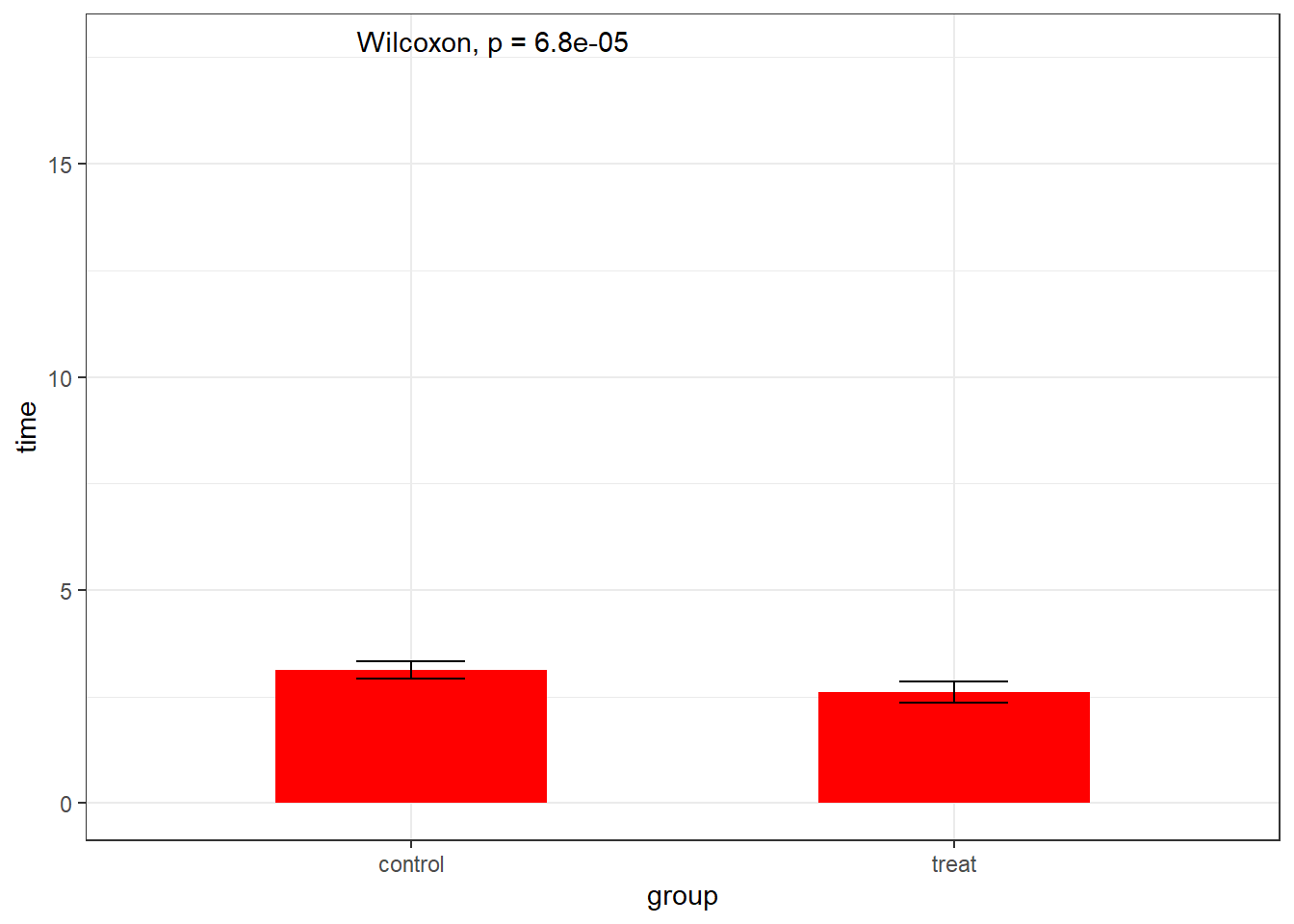
Compare this with the traditional presentation:
library(ggpubr) # includes the stat_compare_means functionggplot(walkingdata, aes(x=group, y=time)) +stat_summary(geom="col", width=0.5, fill="red") +stat_summary(geom="errorbar", width=.2) +scale_x_discrete(na.translate=FALSE) +theme_bw() +stat_compare_means()
Could you say what the treatment effect is by looking at this graph? How sure would you be about it? Also, how would you represent a model other than a simple comparison of means (for example, the multiple linear regression model that we estimated). By confusing the descriptive with the inferential graph we are limiting our ability to conduct the appropriate statistical analysis.
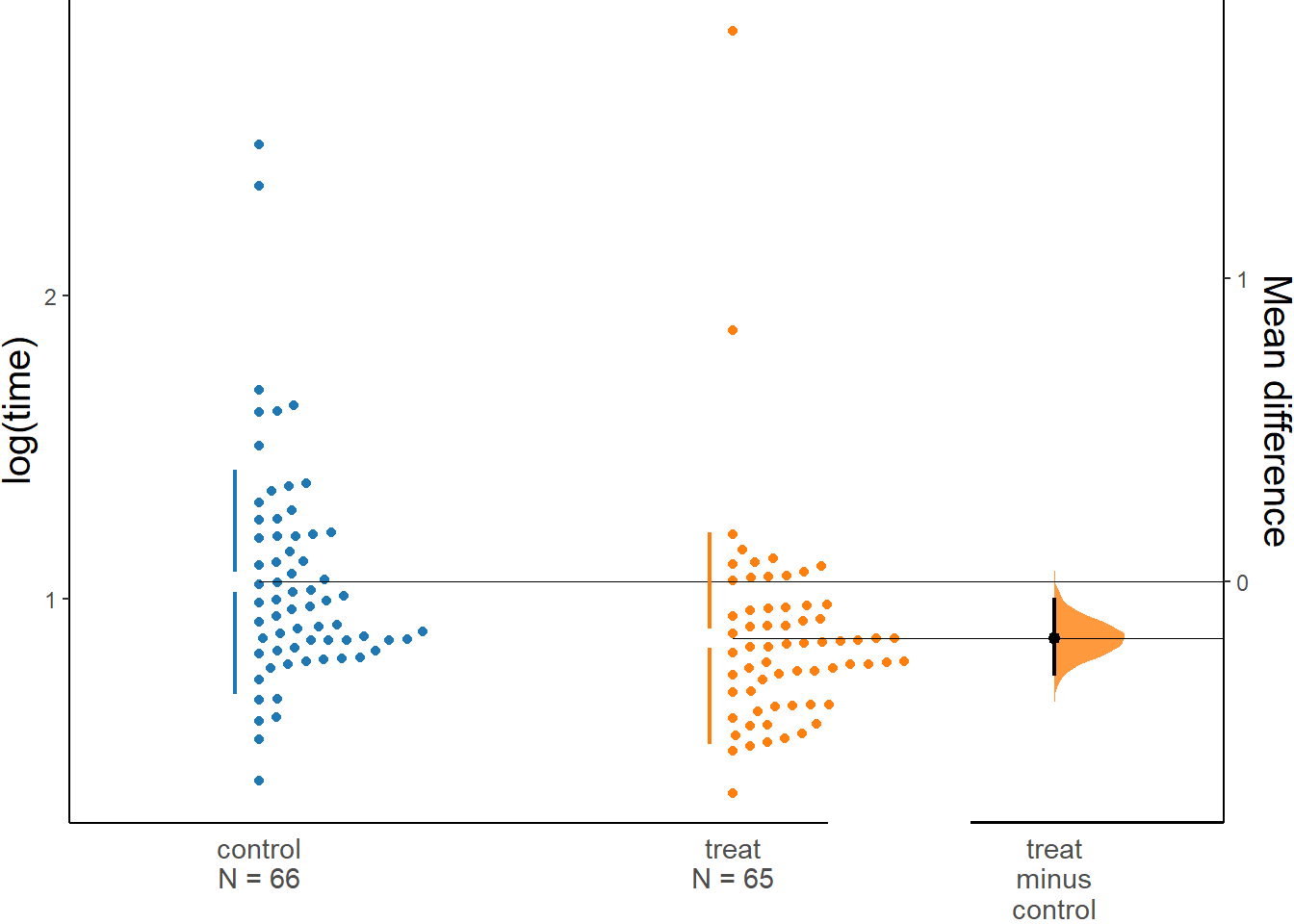
An even better plot might be a Gardner-Altman estimation plot. It is unusual, but implemented in the R package dabestr.
Note that this plot allows us to see the distributions of the data in both groups, but crucially also an estimate of the difference between the groups and the uncertainty around that. A downside is that we cannot accommodate the adjustment for sex or department that was included in the model.
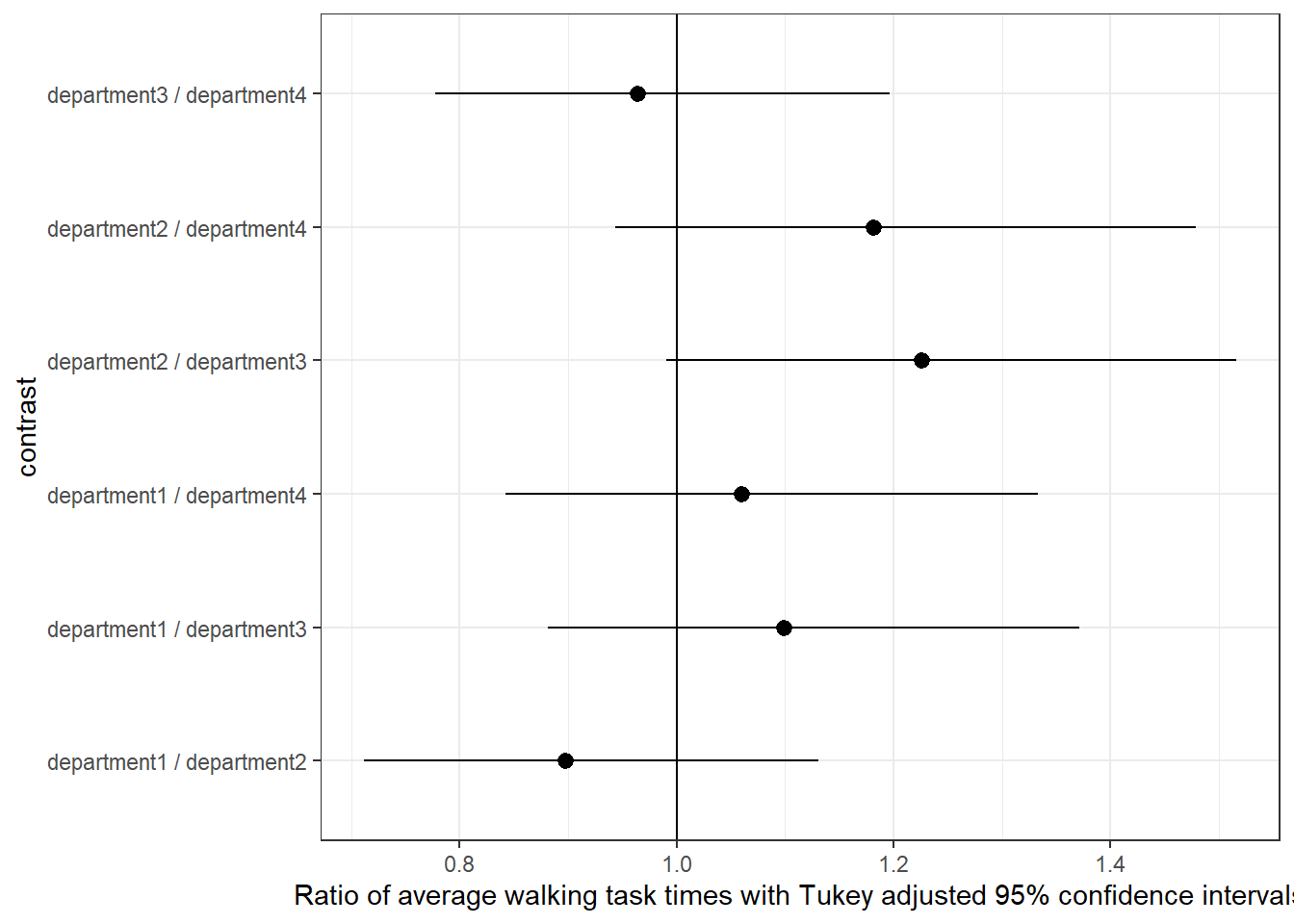
If we did want to show the adjusted estimates, and compare estimates with each other as well as a null hypothesis, then we could use a forest plot. For example, suppose we wanted to compare several groups, say walking speed over department, then a visualisation like this might be useful.
# A tibble: 6 × 11
term contrast null.value ratio std.error df conf.low conf.high null
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 department departme… 0 0.897 0.0797 124 0.712 1.13 1
2 department departme… 0 1.10 0.0933 124 0.881 1.37 1
3 department departme… 0 1.06 0.0933 124 0.843 1.33 1
4 department departme… 0 1.23 0.100 124 0.991 1.52 1
5 department departme… 0 1.18 0.102 124 0.944 1.48 1
6 department departme… 0 0.964 0.0798 124 0.777 1.20 1
# ℹ 2 more variables: statistic <dbl>, adj.p.value <dbl>
ggplot(td) +aes(x=contrast, y=ratio, ymax=conf.high, ymin=conf.low) +geom_pointrange() +coord_flip() +geom_hline(yintercept=1) +theme_bw() +labs(y="Ratio of average walking task times with Tukey adjusted 95% confidence intervals")
What might improve this graph here? Perhaps an annotation for which side of the graph corresponds to faster and which to slower. It is possible to work it out, but if you can avoid that cognitive load for your readers then that would be better!
Finally, some tips for making a good graph
Consider a horizontal layout - key comparisons should be made vertically.
Avoid colour. If you need to use colour, then use colorblind safe palettes.
Never use ‘dynamite’ charts (bar charts with error bars overlaid)
Plot your individual data points where you can
Plot estimates and confidence intervals of important estimands (the things we are trying to estimate), not groups
Don’t use pie charts
Legends should be avoided if possible, but are sometimes essential. Directly annotate if you can.
Maps, 3D or animation can really help, but can also get in the way so use with care.
Always label axes fully, and make it clear what error bars correspond to.
Consider your ink/information ratio. Is your graph really needed? Should it be a line of text, or a table?
Use gridlines.
Be careful when trying to represent data and analysis in the same picture.
Never let a graph dictate your analysis.
Check with other people that your graph is easy to understand. Ask them what they understand from it.
Read up on data visualisation!
Many of these points are embodied in this nice tutorial from Cedric Scherer, where he illustrates how a traditional boxplot might be vastly improved by some simple tweaks.